5.6 Trình thu thập thông tin phân tán
Sự bùng nổ thông tin trong kỷ nguyên Internet là một vấn đề khiến nhiều người cảm thấy đau đầu. Vô số tin tức, thông tin và video đang xâm chiếm dần thời gian của chúng ta. Mặt khác, khi chúng ta thực sự cần dữ liệu, chúng ta cảm thấy rằng dữ liệu không dễ dàng gì có được. Ví dụ: chúng ta muốn biết về những gì mọi người đang thảo luận và quan tâm. Nhưng chúng ta không có thời gian để đọc từng diễn dàn được yêu thích, lúc này chúng ta muốn sử dụng công nghệ để đưa những thông tin cần vào cơ sở dữ liệu. Quá trình này có thể tốn một vài tháng hoặc một năm. Cũng có thể chúng ta muốn lưu những thông tin hữu ích mà vô tình gặp trên Internet như các cuộc thảo luận chất lượng cao của những người tài năng được tập hợp trong một diễn đàn rất nhỏ. Vào một lúc nào đó trong tương lai, chúng ta tìm lại được những thông tin đó và rút ra được những kết luận giá trị mà đến lúc này mới nhận ra.
Ngoài nhu cầu giải trí, có rất nhiều tài liệu mở quý giá trên Internet. Trong những năm gần đây, Deep learning đã và đang rất hot, và machine learning thường không quan tâm đến việc thiết lập ban đầu đúng hay không, các thông số có được điều chỉnh chính xác không, mà là ở giai đoạn khởi tạo ban đầu: không có dữ liệu.
Việc có một chương trình phục vụ việc thu thập thông tin hiện nay rất quan trọng.
5.6.1 Trình thu thập thông tin độc lập dựa trên Collly
Ví dụ sau đưa ra một ví dụ về trình thu thập thông tin đơn giản sử dụng thư viện Collly. Việc dùng Go sẽ cực kì thuận tiện để viết một trình thu thập thông tin cho trang web, chẳng hạn như việc thu thập thông tin trang web (www.abcdefg.com là trang web ảo):
main.go
package main
import (
"fmt"
"regexp"
"time"
"github.com/gocolly/colly"
)
var visited = map[string]bool{}
func main() {
// tạo đối tượng collector
c := colly.NewCollector(
colly.AllowedDomains("www.abcdefg.com"),
colly.MaxDepth(1),
)
// giả sử phù hợp với với regex sau là trang chi tiết
detailRegex, _ := regexp.Compile(`/go/go\?p=\d+$`)
// giả sử phù hợp với với regex sau là danh sách các trang
listRegex, _ := regexp.Compile(`/t/\d+#\w+`)
// tất cả các thẻ đều có hàm callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// duyệt qua từng trang chi tiết hoặc list trang
if visited[link] && (detailRegex.Match([]byte(link)) || listRegex.Match([]byte(link))) {
return
}
// nếu không phải trang chi tiết hoặc danh sách trang thì bỏ qua.
if !detailRegex.Match([]byte(link)) && !listRegex.Match([]byte(link)) {
println("not match", link)
return
}
// hầu hết các trang web đều có chức năng chặn
// cần có thời gian chờ.
time.Sleep(time.Second)
println("match", link)
visited[link] = true
time.Sleep(time.Millisecond * 2)
c.Visit(e.Request.AbsoluteURL(link))
})
err := c.Visit("https://www.abcdefg.com/go/go")
if err != nil {fmt.Println(err)}
}
5.6.2 Trình thu thập thông tin phân tán
Hãy tưởng tượng rằng hệ thống phân tích thông tin của bạn đang chạy rất nhanh. Tốc độ thu thập thông tin đã trở thành nút cổ chai. Mặc dù bạn có thể sử dụng tất cả các tính năng xử lý đồng thời tuyệt vời của Go để dùng hết hiệu suất CPU và băng thông mạng, nhưng bạn vẫn muốn tăng tốc độ thu thập thông tin của trình thu thập thông tin. Trong nhiều ngữ cảnh, tốc độ mang nhiều ý nghĩa:
- Đối với thương mại điện tử, cụ thể là cuộc chiến giá cả, tôi sẽ hy vọng mình có được giá mới nhất của đối thủ khi chúng thay đổi, và hệ thống sẽ tự động điều chỉnh giá của sản phẩm của tôi lại sao cho phù hợp.
- Đối với các dịch vụ cung cấp thông tin
Feed, tính kịp thời của thông tin rất quan trọng. Nếu tin tức thu thập là tin tức của ngày hôm qua, nó sẽ không có ý nghĩa gì với người dùng.
Vì vậy, chúng ta cần hệ thống thu thập thông tin phân tán. Về bản chất, các trình thu thập thông tin phân tán là tập hợp của một hệ thống phân phối và thực thi tác vụ. Trong các hệ thống phân phối tác vụ phổ biến, sẽ có sự sai lệch tốc độ giữa upstream và downstream nên sẽ luôn tồn tại một hàng đợi tin nhắn.
Công việc chính của upstream là thu thập thông tin tất cả các "trang" đích từ một điểm bắt đầu được cấu hình sẵn. Nội dung html của trang danh sách sẽ chứa các liên kết đến các trang chi tiết. Số lượng trang chi tiết thường gấp 10 đến 100 lần so với trang danh sách, vì vậy chúng ta xem các trang chi tiết này như "tác vụ" và phân phối chúng thông qua hàng đợi tin nhắn.
Để thu thập thông tin trang, điều quan trọng là không có sự lặp lại xảy ra thường xuyên trong quá trình thực thi, vì nó sẽ tạo các kết quả sai (ví dụ trên sẽ chỉ thu thập nội dung trang chứ không phải phần bình luận).
Trong phần này, chúng ta sẽ hiện thực trình thu thập thông tin đơn giản dựa trên hàng đợi tin nhắn. Cụ thể ở đây là sử dụng các NATS để phân phối tác vụ. Trong thực tế, tuỳ vào yêu cầu về độ tin cậy của thông điệp và cơ sở hạ tầng của công ty nên sẽ ảnh hưởng tới việc chọn công nghệ của từng doanh nghiệp.
5.6.2.1 Giới thiệu về NATS
NATS là một hàng đợi tin nhắn phân tán (distributed message queue) hiệu năng cao được lập trình bằng Go, ta nên sử dụng nó cho các tình huống yêu cầu tính đồng thời cao, thông lượng cao. Những phiên bản NATS ban đầu mang thiên hướng về tốc độ và không hỗ trợ tính persistence. Kể từ 16 năm trước, NATS đã hỗ trợ tính persistence dựa trên log thông qua NATS Streaming, cũng như nhắn tin đáng tin cậy. Dưới đây là những ví dụ đơn giản về NATS.
Máy chủ của NATS là gnatsd. Phương thức giao tiếp giữa máy khách và gnatsd là giao thức văn bản dựa trên tcp:
Gửi tin nhắn đi có chứa chủ đề cho một tác vụ:
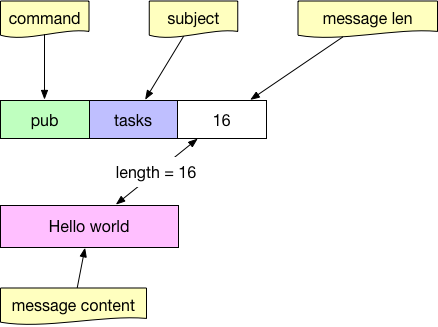
Pub trong giao thức NATS
Theo dõi các tác vụ bằng chủ đề trên hàng đợi của các worker:
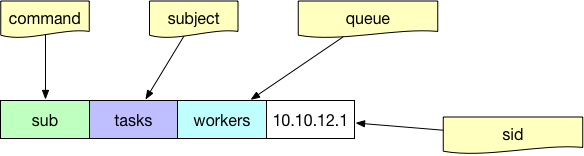
Sub trong giao thức NATS
Tham số hàng đợi là tùy chọn. Nếu bạn muốn cân bằng tải các tác vụ ở phía người dùng, thay vì tất cả mọi người nhận cùng một kênh, bạn nên gán một tên hàng đợi cho một người dùng.
Sản xuất tin nhắn
Sản xuất tin nhắn được chỉ định bằng topic:
nc, err := nats.Connect(nats.DefaultURL)
if err != nil {return}
// tham số đầu tiên tasks là tên topic
// tham số tiếp theo là nội dung tin nhắn gửi đi
err = nc.Publish("tasks", []byte("your task content"))
nc.Flush()
Tiêu thụ tin nhắn
Việc sử dụng trực tiếp API đăng ký của Nats không thể thoả được mục đích phân phối tác vụ, vì pub-sub là broadcast nên tất cả consumer sẽ nhận được cùng một thông điệp.
Ngoài cách đăng ký bình thường, Nats đã cung cấp chức năng đăng ký hàng đợi. Bằng cách cung cấp tên nhóm hàng đợi (tương tự như nhóm comsumer trong Kafka), các tác vụ có thể được phân phối cho consumer một cách cân bằng.
nc, err := nats.Connect(nats.DefaultURL)
if err != nil {return}
// đăng kí hàng đợi đồng nghĩa với việc giúp cho hệ thống cân bằng tải cho việc phân phốitask.
// hng đợi trong Nats tương tự về mặt khái niệm với group consumber ở Kafka
sub, err := nc.QueueSubscribeSync("tasks", "workers")
if err != nil {return}
var msg *nats.Msg
for {
msg, err = sub.NextMsg(time.Hour * 10000)
if err != nil {break}
// xử lý tin nhắn nhận được
}
5.6.3 Tạo tin nhắn bằng cách kết hợp NATS và Colly
Bên dưới là một trình thu thập được tuỳ chỉnh cho trang web là www.abcdefg.com, www.hijklmn.com (ví dụ bên dưới), và sử dụng một phương thức factory đơn giản để ánh xạ trình thu thập tới đúng server. Khi trang web đang duyệt là một trang danh sách, ta cần phân tích tất cả các liên kết trong trang hiện tại và gửi liên kết của trang chi tiết đến hàng đợi tin nhắn.
Mô hình hoạt động:

main.go
package main
import (
"fmt"
"net/url"
"github.com/gocolly/colly"
)
var domain2Collector = map[string]*colly.Collector{}
var nc *nats.Conn
var maxDepth = 10
var natsURL = "nats://localhost:4222"
func factory(urlStr string) *colly.Collector {
u, _ := url.Parse(urlStr)
return domain2Collector[u.Host]
}
func initABCDECollector() *colly.Collector {
c := colly.NewCollector(
colly.AllowedDomains("www.abcdefg.com"),
colly.MaxDepth(maxDepth),
)
c.OnResponse(func(resp *colly.Response) {
// thực hiện một số xác nhận
// ví dụ như xác nhận trang đã thu thập thông tin đã được lưu ở MySQL
})
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// chiến lược chống anti-reptile
link := e.Attr("href")
time.Sleep(time.Second * 2)
// duyệt qua list trang thông thường
if listRegex.Match([]byte(link)) {
c.Visit(e.Request.AbsoluteURL(link))
}
// gửi các liên kết trong list trang vào hàng đợi tin nhắn
if detailRegex.Match([]byte(link)) {
err = nc.Publish("tasks", []byte(link))
nc.Flush()
}
})
return c
}
func initHIJKLCollector() *colly.Collector {
c := colly.NewCollector(
colly.AllowedDomains("www.hijklmn.com"),
colly.MaxDepth(maxDepth),
)
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
})
return c
}
func init() {
domain2Collector["www.abcdefg.com"] = initV2exCollector()
domain2Collector["www.hijklmn.com"] = initV2fxCollector()
var err error
nc, err = nats.Connect(natsURL)
if err != nil {os.Exit(1)}
}
func main() {
urls := []string{"https://www.abcdefg.com", "https://www.hijklmn.com"}
for _, url := range urls {
instance := factory(url)
instance.Visit(url)
}
}
5.6.4 Kết hợp trình tiêu thụ tin nhắn với Collly
Phía consumer sẽ đơn giản hơn, chúng ta chỉ cần đăng ký chủ đề tương ứng và truy cập trực tiếp vào trang chi tiết.
main.go
package main
import (
"fmt"
"net/url"
"github.com/gocolly/colly"
)
var domain2Collector = map[string]*colly.Collector{}
var nc *nats.Conn
var maxDepth = 10
var natsURL = "nats://localhost:4222"
func factory(urlStr string) *colly.Collector {
u, _ := url.Parse(urlStr)
return domain2Collector[u.Host]
}
func initV2exCollector() *colly.Collector {
c := colly.NewCollector(
colly.AllowedDomains("www.abcdefg.com"),
colly.MaxDepth(maxDepth),
)
return c
}
func initV2fxCollector() *colly.Collector {
c := colly.NewCollector(
colly.AllowedDomains("www.hijklmn.com"),
colly.MaxDepth(maxDepth),
)
return c
}
func init() {
domain2Collector["www.abcdefg.com"] = initABCDECollector()
domain2Collector["www.hijklmn.com"] = initHIJKLCollector()
var err error
nc, err = nats.Connect(natsURL)
if err != nil {os.Exit(1)}
}
func startConsumer() {
nc, err := nats.Connect(nats.DefaultURL)
if err != nil {return}
sub, err := nc.QueueSubscribeSync("tasks", "workers")
if err != nil {return}
var msg *nats.Msg
for {
msg, err = sub.NextMsg(time.Hour * 10000)
if err != nil {break}
urlStr := string(msg.Data)
ins := factory(urlStr)
// vì phần downstream chắc chắn là trang chi tiết nên chỉ cần lấy thông tin từ trang này
ins.Visit(urlStr)
// prevent being blocked
time.Sleep(time.Second)
}
}
func main() {
startConsumer()
}
Về cơ bản, khi lập trình thì các producer và consumer là giống nhau. Nếu chúng ta muốn có tính linh hoạt trong việc tăng và giảm số các trang web để thu thập thông tin trong tương lai, chúng ta nên suy nghĩ về các tham số và chiến lược cấu hình cho trình thu thập thông tin càng nhiều càng tốt.
Việc sử dụng hệ thống cấu hình đã được đề cập trong phần cấu hình phân tán nên các bạn có thể tự mình dùng thử nó.
Liên kết
- Phần tiếp theo: Lời nói thêm
- Phần trước: Quản lý cấu hình trong hệ thống phân tán
- Mục lục