5.1 Distributed ID generator
Đôi khi chúng ta cần tạo ra một ID tương tự như ID tăng tự động của MySQL và có tính chất không được trùng lặp. Chúng ta có thể sử dụng ID để hỗ trợ các ngữ cảnh trong kinh doanh. Điển hình, khi có chương trình khuyến mãi trong thương mại điện tử, một số lượng lớn đơn đặt hàng sẽ tràn vào hệ thống trong một khoảng thời gian ngắn, tạo ra khoảng 10 ngàn đơn mỗi giây, mỗi đơn sẽ tương ứng với một ID định danh.
Trước khi chèn vào cơ sở dữ liệu, chúng ta cần cung cấp cho các thông tin đó một ID, sau đó chèn nó vào cơ sở dữ liệu. Yêu cầu đối với ID này là có thông tin về thời gian. Nhờ vậy, cơ sở dữ liệu của chúng ta vẫn có thể sắp xếp các tin nhắn đó theo thứ tự thời gian.
Thuật toán snowflake của Twitter là giải pháp điển hình trong ngữ cảnh này. Hãy nhìn vào hình sau:
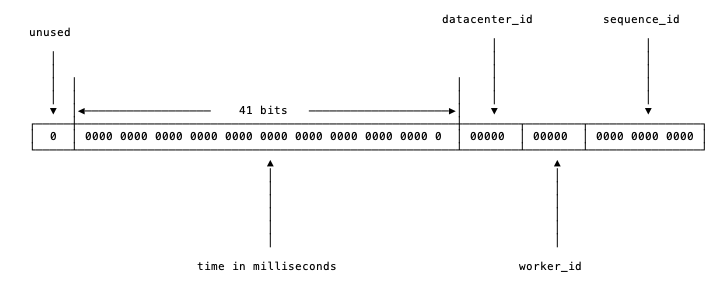
Phân phối Bit trong snowflake
Đầu tiên, ta xác định rằng giá trị là 64 bit, kiểu dữ liệu tương ứng bên Go là int64, chúng được chia thành bốn phần:
- Không sử dụng bit đầu tiên vì bit này là bit dấu.
timestamp: sử dụng 41 bit để biểu thị timestamp khi nhận được yêu cầu, tính bằng milliseconds.datacenter_id: 5 chữ số để biểu thị id của trung tâm dữ liệu.worker_id: 5 chữ số để biểu thị id của server.sequence_id: cuối cùng là id tăng vòng lặp 12 bit ( tăng từ 0 đến 111111111111 rồi trở về 0).
Cơ chế này có thể hỗ trợ chúng ta tạo ra 2 ^ 12 = 4096 tin nhắn trong cùng một millisecond trên cùng một server. Vậy chúng ta có tổng cộng có 4096 triệu tin nhắn trong một giây. Nó là hoàn toàn đủ để sử dụng trong các trường hợp cần một số lượng ID lớn trong thời gian ngắn.
timestamp gồm 41 chữ số nên có thể hỗ trợ chúng ta trong 69 năm. Tất nhiên, thời gian tính bằng mili giây của chúng ta có thể không thực sự bắt đầu từ năm 1970, vì nếu như vậy thì hệ thống sẽ chỉ hoạt động đến 2039/9/7 23:47:35 , do đó, chúng chỉ nên tăng so với một mốc thời gian nhất định. Ví dụ: hệ thống của chúng ta là bắt đầu chạy vào 2018-08-01, thì chúng ta có thể coi mốc thời gian này là 2018-08-01 00: 00: 00.000 và tăng lên từ đó.
5.1.1 Phân công worker_id
timestamp, datacenter_id, worker_id và sequence_id là bốn trường, riêng timestamp và sequence_id được tạo bởi chương trình khi chạy. Còn datacenter_id và worker_id cần lấy trong giai đoạn triển khai và khi chương trình đã được khởi động, nó không thể thay đổi.
Nhìn chung, các server trong các trung tâm dữ liệu khác nhau sẽ cung cấp các API tương ứng để lấy id của trung tâm dữ liệu, vì vậy datacenter_id có thể dễ dàng lấy trong giai đoạn triển khai. Còn worker_id là một id mà chúng ta gán một cách "logically" cho từng máy. Chúng ta nên xử lý thế nào? Ý tưởng đơn giản là sử dụng các công cụ cung cấp tính năng ID tự tăng, chẳng hạn như trong MySQL:
mysql> insert into a (ip) values("10.1.2.101");
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 2 |
+------------------+
1 row in set (0.00 sec)
Khi bạn đã nhận được ID từ MySQL, worker_id sẽ được duy trì cục bộ, tránh được trường hợp làm mới mỗi khi bạn truy cập worker_id.
Tất nhiên, sử dụng MySQL đồng nghĩa với việc thêm một phụ thuộc bên ngoài vào service tạo ID. Chúng ta đều biết việc càng thêm nhiều phụ thuộc, khả năng phục vụ của service càng tệ.
Xem xét đến việc có một service tạo ID bị lỗi trong cluster, một phần của ID bị mất trong một khoảng thời gian, thì chúng ta cần gắn trực tiếp worker_id vào cấu hình của worker. Khi hệ thống đó hoạt động lại, đoạn script triển khai sẽ quy định giá trị worker_id.
5.1.2 Các Open source hiện có
5.1.2.1 Hiện thực theo snowflake chuẩn
Snowflake là một hiện thực Snowflake của Go khá nhẹ. Bạn có thể sử dụng phần định nghĩa của nó, xem dưới đây.

Thư viện snowflake
Nó giống hoàn toàn như snowflake tiêu chuẩn. Và tương đối đơn giản để sử dụng như ví dụ sau:
main.go
package main
import (
"fmt"
"os"
"github.com/bwmarrin/snowflake"
)
func main() {
// khởi tại một node
n, err := snowflake.NewNode(1)
if err != nil {
println(err)
os.Exit(1)
}
for i := 0; i < 3; i++ {
// tạo ID
id := n.Generate()
fmt.Println("id", id)
fmt.Println(
"node: ", id.Node(),
"step: ", id.Step(),
"time: ", id.Time(),
"\n",
)
}
}
// output:
// id 1160090501362225152
// node: 1 step: 0 time: 1565422103621
// id 1160090501362225153
// node: 1 step: 1 time: 1565422103621
// id 1160090501362225154
// node: 1 step: 2 time: 1565422103621
Dĩ nhiên, thư viện này cũng cho phép chúng ta tùy chỉnh vài thông số, các trường có thể tùy chỉnh như:
// Epoch là thời gian bắt đầu
// Epoch được thiết lập theo twitter snowflake epoch vào thởi điểm Nov 04 2010 01:42:54 UTC
// bạn có thể thiết lập Epoch theo thời gian của ứng dụng của bạn.
Epoch int64 = 1288834974657
// độ dài bit của máy chủ hoạt động
// nhớ rằng, bạn có tổng 22 bits chia sẻ giữa Node/Step
NodeBits uint8 = 10
// số bit để sử dụng cho Step
StepBits uint8 = 12
5.1.2.2 Sonyflake
Sonyflake là một dự án Open source của Sony. Ý tưởng cơ bản tương tự như snowflake, nhưng phân bổ bit hơi khác.

Sonyflake
Thời gian ở đây chỉ sử dụng 39 bit, nhưng đơn vị thời gian trở thành 10ms. Về mặt lý thuyết, nó dài hơn thời gian của snowflake chuẩn đến 41 bit (174 năm).
Sequence ID giống với với định nghĩa trước đó, Machine ID thực sự là id của Node. Sự khác biệt giữa sonyflake là các tham số cấu hình trong quá trình khởi động:
Cấu trúc của Settings như sau:
type Settings struct {
// tương tự như Epoch
// mặc định bắt đầu vào ngày 2014-09-01 00:00:00 +0000 UTC
StartTime time.Time
// hàm do người dùng định nghĩa
// mặc định là 16bit cuối của IP gốc
MachineID func() (uint16, error)
// hàm kiểm tra MachineID có trùng hay không
CheckMachineID func(uint16) bool
}
Sử dụng CheckMachineID là thiết kế khá thông minh. Nếu có một bộ lưu trữ tập trung và hỗ trợ kiểm tra sự trùng lặp, thì chúng ta có thể tùy chỉnh logic để kiểm tra xem MachineID có trùng không. Nếu công ty có cụm Redis được tạo sẵn, thì chúng dễ dàng kiểm tra trùng bằng các loại collection của Redis.
Redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 1
Redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 0
main.go
package main
import (
"fmt"
"os"
"time"
"github.com/sony/sonyflake"
)
// getMachineID hàm lấy MachineID
func getMachineID() (uint16, error) {
var machineID uint16
var err error
// đọc MachineID từ file ở local
machineID = readMachineIDFromLocalFile()
if machineID == 0 {
// nếu không có
// gọi hàm generateMachineID để tạo ID
machineID, err = generateMachineID()
If err != nil {
return 0, err
}
}
return machineID, nil
}
// checkMachineID hàm kiểm tra MachineID có trùng không
func checkMachineID(machineID uint16) bool {
// thêm machineID vào redis
saddResult, err := saddMachineIDToRedisSet()
if err != nil || saddResult == 0 {
return true
}
// lưu lại machineID xuống file ở local
err := saveMachineIDToLocalFile(machineID)
if err != nil {
return true
}
return false
}
func main() {
t, _ := time.Parse("2006-01-02", "2018-01-01")
// khởi tạo struct setting
settings := sonyflake.Settings{
StartTime: t,
MachineID: getMachineID,
CheckMachineID: checkMachineID,
}
// tạo sonyflake struct
sf := sonyflake.NewSonyflake(settings)
// lấy ID
id, err := sf.NextID()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println("ID: ", id)
}
// output:
// ID: 84989976554504193
Liên kết
- Phần tiếp theo: Lock phân tán (Distributed lock)
- Phần trước: Chương 5: Distributed System
- Mục lục