4.5 Làm việc với Database
Phần này sẽ phân tích các thư viện database/sql tiêu chuẩn, giới thiệu một số ORM (Object Relational Mapping) và SQL Builder Open source được sử dụng rộng rãi. Cuối cùng là đánh giá công nghệ nào phù hợp nhất đứng ở góc độ phát triển ứng dụng doanh nghiệp.
4.5.1 Bắt đầu từ database/sql
Go cung cấp một package database/sql để làm việc với cơ sở dữ liệu cho người dùng. Package này cung cấp một interface và các hàm để vận hành cơ sở dữ liệu như quản lý nhóm kết nối, liên kết dữ liệu (data binding), transaction, xử lý lỗi, và vài chức năng khác.
Để giao tiếp với một cơ sở dữ liệu nhất định như MySQL, bạn phải cung cấp driver MySQL như sau:
import "database/sql"
import _ "github.com/go-sql-driver/mysql"
// Open để tạo ra một database handle
db, err := sql.Open("mysql", "user:password@/dbname")
Xem một chút về hàm init:
func init() {
// Register giúp db driver available với "mysql".
// nếu hàm này được gọi 2 lần cùng 1 tên db hoặc
// driver nil sẽ gây ra panic.
sql.Register("mysql", &MySQLDriver{})
}
Interface Driver trong package sql:
type Driver interface {
Open(name string) (Conn, error)
}
sql.Open() trả về đối tượng db từ lời gọi hàm Conn
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}
Trong thực tế, nếu nhìn vào code của database/sql/driver/driver.go sẽ thấy rằng tất cả các thành phần trong file đều là interface cả. Tuỳ vào kiểu trong này mà ta sẽ phải gọi tới những phương thức driver phù hợp.
Ở phía người dùng, trong process sử dụng package databse/sql, ta có thể sử dụng các hàm được cung cấp trong những interface kể trên, hãy nhìn vào một ví dụ hoàn chỉnh sử dụng database/sql và go-sql-driver/mysql:
package main
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// db là một đối tượng của kiểu sql.DB,
// tùy chọn kết nối có thể được đặt trong phương thức sql.DB, ở đây bỏ qua
db, err := sql.Open("mysql","user:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
defer db.Close()
var (
id int
name string
)
// Query thực thi câu query và trả về các rows.
rows, err := db.Query("select id, name from users where id = ?", 1)
if err != nil {
log.Fatal(err)
}
// giải phóng kết nối khi rows.Close() thực thi
defer rows.Close()
// Next chuẩn bị row kết quả kế tiếp để đọc với Scan
for rows.Next() {
err := rows.Scan(&id, &name)
if err != nil {
log.Fatal(err)
}
log.Println(id, name)
}
// Err trả về lỗi nếu có trong quá trình lặp
err = rows.Err()
if err != nil {
log.Fatal(err)
}
}
Nếu bạn đọc muốn biết database/sql chi tiết hơn, có thể xem tại http://go-database-sql.org/.
Một vài hiện thực bao gồm các hàm, giới thiệu, cách sử dụng, các cảnh báo và các phản trực quan (counter-intuition) về thư viện (ví dụ như sql.DB, các truy vấn trong cùng goroutine có thể ở trên nhiều connections) đều được đề cập, và chúng sẽ không được nhắc tới nữa trong chương này.
Có thể thấy rằng hàm cung cấp db của thư viện chuẩn quá đơn giản. Chúng ta cần phải viết code SQL mỗi lần truy cập database để đọc dữ liệu, điều này có thể dẫn đến nguy cơ SQL Injection nếu xử lý không cẩn thận.
Sau đây sẽ là 2 cách khác để làm điều tương tự: SQL Builder và ORM.
4.5.2 Dùng ORM để tăng hiệu suất
Hãy xem định nghĩa của ORM trên wikipedia:
Object-relational mapping (ORM, O/RM, and O/R mapping tool) trong khoa học máy tính là một kĩ thuật lập trình cho phép chuyển đổi dữ liệu giữa các hệ thống kiểu không tương thích bằng ngôn ngữ hướng đối tượng. Điều này tạo ra một "cơ sở dữ liệu hướng đối tượng ảo" có thể được sử dụng từ trong ngôn ngữ lập trình.
Thông thường ORM thực hiện việc mapping từ database tới các class hoặc struct của chương trình.
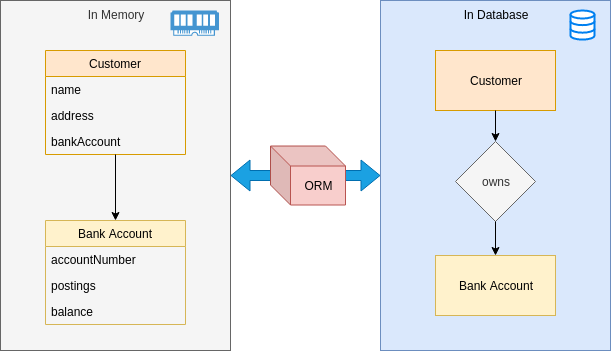
Minh hoạ mapping giữa Database và Struct trong memory
Mục đích của ORM là che chắn lớp DB khỏi người sử dụng. ORM định nghĩa class hoặc struct, sau đó sử dụng một cú pháp cụ thể để tạo ra struct tương ứng 1-1. Sau đó, ta có thể thực hiện các thao tác khác nhau trên các đối tượng đã map từ các bảng trong cơ sở dữ liệu như SAVE, CREATE, DELETE,... . Đối với những gì ORM đã thực hiện ẩn bên dưới, ta không cần phải rõ ràng. Khi sử dụng ORM, chúng ta thường sẽ không quan tâm cơ sở dữ liệu.
Ví dụ: ta có nhu cầu hiển thị cho người dùng danh sách sản phẩm mới nhất, giả định rằng product và shop có mối quan hệ 1:1, có thể thể hiện bằng đoạn code sau:
# mã giả
shopList := []
for product in productList {
shopList = append(shopList, product.GetShop)
}
Công cụ như ORM là để bảo vệ cơ sở dữ liệu ngay từ điểm bắt đầu, cho phép vận hành cơ sở dữ liệu gần hơn với cách suy nghĩ của con người. Vì vậy, nhiều lập trình viên dù mới tiếp xúc với ORM cũng có thể code được.
Đoạn code trên sẽ phóng to yêu cầu đọc cơ sở dữ liệu theo hệ số của N. Nói cách khác, nếu danh sách sản phẩm có 15 SKU (Stock-Keeping Unit), mỗi lần người dùng mở trang, ít nhất 1 (danh sách mục truy vấn) + 15 (yêu cầu thông tin cửa hàng liên quan đến truy vấn) là bắt buộc. Ở đây N là 16. Nếu trang danh sách khá lớn, giả sử 600 mục, thì ta phải thực hiện ít nhất 1 + 600 truy vấn.
Nếu số lượng truy vấn đơn giản lớn nhất mà cơ sở dữ liệu có thể chịu được là 120 000 QPS và truy vấn trên chỉ là truy vấn được sử dụng phổ biến nhất, thì khả năng service có thể cung cấp là bao nhiêu? 200 QPS! Một trong những nguyên tắc cấm kỵ của các hệ thống trên Internet là sự khuếch đại số lượng thao tác đọc không cần thiết này.
Tất nhiên bạn có thể nói rằng đó không phải là vấn đề của ORM. Nếu viết bằng sql ta vẫn có thể viết được một chương trình giống vậy, hãy nhìn vào demo sau:
o := orm.NewOrm()
num, err := o.QueryTable("cardgroup").Filter("Cards__Card__Name", cardName).All(&cardgroups)
Nhiều ORM cung cấp kiểu truy vấn Filter này, nhưng trên thực tế, đằng sau ORM còn ẩn nhiều thao tác chi tiết khác, chẳng hạn như tạo ra câu lệnh SQL tự động limit 1000.
Có lẽ nhiều người trong chúng ta không hề biết có thao tác đó. Thực ra trong tài liệu chính thức của ORM đã nói qua rằng tất cả các truy vấn sẽ tự động limit 1000 mà không cần chỉ định rõ, chính vì vậy mà điều này trở nên khó khăn đối với nhiều người chưa đọc tài liệu hoặc đọc mã nguồn của ORM. Những lập trình viên thích ngôn ngữ ràng buộc kiểu mạnh thường không thích những gì ngôn ngữ tự thực hiện ngầm định, chẳng hạn như chuyển đổi kiểu ngầm của các ngôn ngữ khác nhau trong thao tác gán để rồi mất đi độ chính xác trong chuyển đổi, điều này chắc chắn sẽ khiến họ đau đầu. Vì vậy, càng có ít thứ mà thư viện làm ẩn bên dưới thì càng tốt. Nếu ta cần thực hiện điều gì hãy thực hiện nó ở một nơi dễ thấy. Trong ví dụ trên, tốt hơn hết là loại bỏ hành vi tự hành động ngầm định này hoặc là bắt buộc người dùng phải truyền vào tham số limit.
Ngoài vấn đề litmit, chúng ta hãy xem truy vấn này dưới đây:
num, err := o.QueryTable("cardgroup").Filter("Cards__Card__Name", cardName).All(&cardgroups)
Bạn có thấy rằng Filter này là một thao tác JOIN không? Rất khó để nhận ra vì ORM đã che giấu quá nhiều chi tiết khỏi thiết kế. Cái giá của sự tiện lợi là những hoạt động ẩn đằng sau nó hoàn toàn nằm ngoài kiểm soát. Một dự án như vậy sẽ trở nên ngày càng khó theo dõi và bảo trì chỉ sau một vài lần nâng cấp.
Tất nhiên chúng ta không thể phủ nhận được tầm quan trọng của ORM. Mục đích ban đầu của nó là loại bỏ việc triển khai cụ thể các hoạt động với database và lưu trữ dữ liệu. Nhưng một số công ty đã dần xem ORM là một thiết kế thất bại vì các chi tiết quan trọng bị ẩn giấu khá nhiều. Các chi tiết này rất quan trọng đối với sự phát triển về lâu dài của các hệ thống cần mở rộng quy mô.
4.5.3 Dùng SQL Builder để tăng hiệu suất
So sánh với ORM, SQL Builder đạt được sự cân bằng tốt hơn giữa SQL và khả năng bảo trì của dự án. Đầu tiên, sql builder không ẩn quá nhiều chi tiết như ORM nhưng cũng khá đơn giản để sử dụng:
// câu truy vấn có điều kiện where
where := map[string]interface{} {
"order_id > ?" : 0,
"customer_id != ?" : 0,
}
limit := []int{0,100}
orderBy := []string{"id asc", "create_time desc"}
// get list kết quả từ các thành phần khởi tạo phía trên
orders := orderModel.GetList(where, limit, orderBy)
Việc code và đọc hiểu SQL Builder đều không gặp khó khăn gì. Chuyển đổi những dòng code này thành sql cũng không cần quá nhiều nỗ lực.
Nói một cách dễ hiểu, SQL Builder là một cách biểu diễn ngôn ngữ đặc biệt của sql trong mã. Nếu bạn không có DBA, nhưng R&D có khả năng phân tích và tối ưu hóa sql hoặc DBA của công ty bạn không phản đối các kiểu ngôn ngữ sql như thế này thì bạn sử dụng SQL Builder là một lựa chọn tốt.
4.5.4 Sử dụng connection pool để tăng hiệu suất
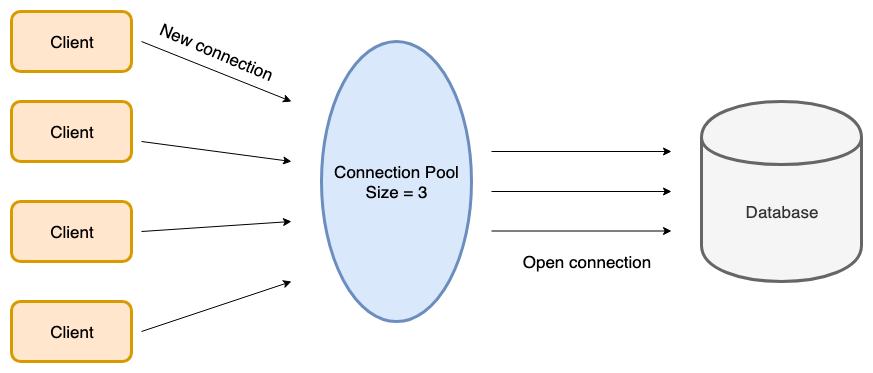
Minh hoạ Connection Pool
Một trong những kĩ thuật quan trọng khi làm việc với database là sử dụng connection pool. Một connection xem như là một bộ đệm duy trì các kết nối tới database. Một connection pool là tập hợp nhiều connection tới database.
Cơ chế hoạt động của connection pool khá đơn giản, khi một connection được tạo thì conneciton đó sẽ được đưa vào pool và được sử dụng lại cho các yêu cầu kết nối tiếp theo cho đến khi bị đóng hoặc hết thời gian chờ (timeout). Khi người dùng gửi yêu cầu gửi đến hệ thống, hệ thống sẽ kiểm tra xem trong pool có connection nào chưa đươc sử dụng không. Có hai trường hợp xảy ra:
- Nếu có conneciton chưa được sử dụng, hệ thống sẽ cung cấp connecion đó cho người dùng để xử lý các yêu cầu kết nối tới database.
- Nếu trong pool không rỗng hoặc không có conneciton nào đang rảnh và số lượng kết nối trong pool vẫn chưa vượt quá số lượng connection quy định (max conneciton) thì hệ thống sẽ tạo một connection mới tới database và cung cấp cho người dùng connection đó.
- Nếu trong pool đã hết connection rảnh và pool đã đạt số lượng conntion cho phép tạo thì người dùng phải đợi cho đến khi có một connection rảnh được đưa vào pool.
Sử dụng connection pool có nhiều ưu điểm:
- Tăng hiệu suất khi làm việc với database, vì chúng ta có nhiều kết nối tới database cùng lúc mà không phải đợi tuần tự.
- Không phải tốn chi phí thời gian khởi tạo conneciton và đóng connection cho mỗi yêu cầu kết nối tới database vì trong pool đã có sẵn connection được khởi tạo rồi.
- Sử dụng tài nguyên hệ thống hợp lý, khi chúng ta có thể tận dụng lại các connection đã sử dụng và giới hạn được số lượng connection được mở.
Khi sử dụng package database/sql, thì mặc định package đã hỗ trợ chúng ta phần connection pool. Nhưng chúng ta có thể cấu hình lại connection pool để sử dụng hiệu quả hơn.
Sử dụng hàm SetMaxOpenConns Cấu hình số lượng connection lớn nhất có thể được mở.
func main() {
db, err := sql.Open("mysql",
"username:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// mặc định là 0 (không giới hạn)
// nếu giá trị truyền vào max <= 0 cũng sẽ là không giới hạn
db.SetMaxOpenConns(10)
}
Sử dụng hàm SetMaxIdleConns Cấu hình số lượng connetion rảnh có trong pool. Chỉ số này luôn nhỏ hơn hoặc bằng chỉ số MaxOpenConns. Nếu chúng ta cấu hình cao hơn thì thư việc sẽ tự điều chỉnh giảm lại cho phù hợp với chỉ số MaxOpenConns.
func main() {
db, err := sql.Open("mysql",
"username:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// mặc định là 2 connection rảnh
// nếu giá trị truyền vào max <= 0 là không có connection rãnh được giữ lại
db.SetMaxIdleConns(10)
}
Sử dụng hàm SetConnMaxLifetime Cấu hình thời gian tối đa của một connection được sử dụng lại. Sau khi hết thời gian quy định thì connection sẽ bị đóng lại.
func main() {
db, err := sql.Open("mysql",
"username:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// mặc định là các connection không bị đóng
// nếu giá trị truyền vào max <= 0 là các connection sẽ được sử dụng lại mãi và không bị đóng
db.SetConnMaxLifetime(10 * time.Hour)
Các bạn có thể tìm hiểu thêm về cấu hình connection pool ở đây.
4.5.5 Sử dụng Prepared Statement để tăng hiệu suất
Để tối ưu hiệu năng của hệ thống, có rất nhiều cách để thực hiện nhưng hiệu quả nhất vẫn là tối ưu các câu truy vấn database. Một trong số này đó là sử dụng prepared statement để truy vấn.
Prepared statement là một tính năng được sử dụng để thực hiện lặp lại các câu lệnh SQL tương tự nhau với hiệu quả cao. Ví dụ minh hoạ sau:
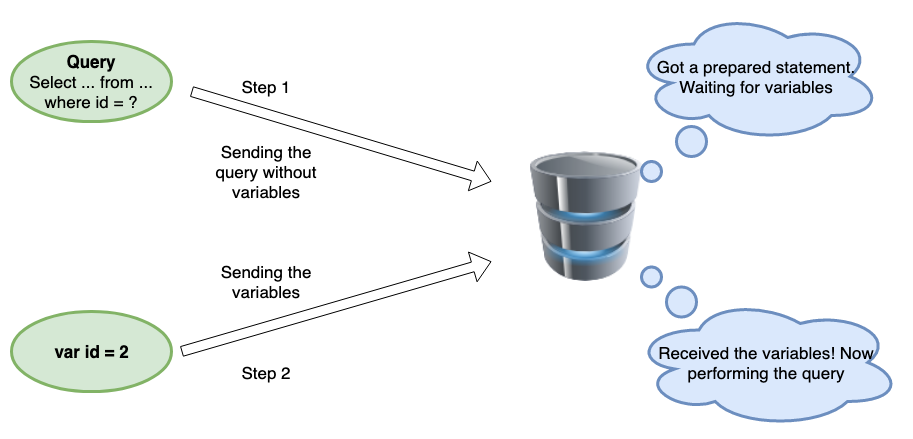
Minh hoạ cơ chế Prepare statemnt
package main
import (
_ "github.com/go-sql-driver/mysql"
"database/sql"
"log"
)
func main(){
db, err := sql.Open("mysql", "root:root@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
stmt, err := db.Prepare("SELECT * FROM accounts WHERE id = ?;")
res,err:=stmt.Exec(2)
res,err=stmt.Exec(3)
if err!=nil{
log.Fatal(err)
}
log.Println(res)
}
- Prepare: đầu tiên, ứng dụng tạo ra 1 statement template và gửi nó cho DBMS. Các giá trị không được chỉ ra và được gọi là
parameters(dấu?bên dưới)SELECT * FROM accounts WHERE id = ?; - Compile: (parse, optimizes và translates) statement template , store kết quả mà không thực thi. Quá trình này do DBMS thực hiện.
- Execute: ứng dụng gửi giá trị của parametes của statement template và DBMS thực thi nó. Ứng dụng có thể thực thi statement nhiều lần với nhiều giá trị khác nhau.
Ưu điểm khi sử dụng prepared statement:
- Overhead của compile statement diễn ra 1 lần còn statement được thực thi nhiều lần. Về lý thuyết, khi sử dụng prepared statement, ta sẽ tiết kiệm được:
cost_of_prepare_preprocessing * (#statement_executions - 1). Nhưng thực tế, tuỳ từng loại query sẽ có cách optimize khác nhau (chi tiết). - Chống SQL injection.
- Phát hiện sớm các lỗi cú pháp trong câu statement.
- Có thể
cache prepared statementvà sử dụng lại sau này.
Các bạn có thể xem chi tiết hơn bài blog này.
Liên kết
- Phần tiếp theo: Giới hạn lưu lượng Service
- Phần trước: Kiểm tra tính hợp lệ của request
- Mục lục