4.6 Giới hạn lưu lượng Service
Một chương trình máy tính có thể mắc phải một số các vấn đề bottleneck (tắc nghẽn):
- Bottleneck do CPU tính toán.
- Bottleneck do băng thông mạng.
- Đôi khi do external system gây ra tình trạng bottleneck trong chính hệ thống phân tán của nó.
Phần quan trọng nhất của một hệ thống Web là mạng. Cho dù đó là tiếp nhận, phân tích request của người dùng, truy cập bộ nhớ hay trả về dữ liệu response đều cần phải truy cập trực tuyến. Trước khi xuất hiện IO multiplexing interface epoll/kqueue do hệ thống cung cấp thì từng có một sự cố C10k trong máy tính đa lõi.
Vấn đề C10k xảy ra khi số lượng client giữ kết nối vượt 10000
Kể từ khi trên Linux có epoll, FreeBSD hiện thực kqueue, chúng ta có thể dễ dàng giải quyết vấn đề C10k với API do kernel cung cấp.
Thư viện net của Go đóng gói các syscall API khác nhau cho các nền tảng khác nhau. Thư viện http được xây dựng trên nền của thư viện net, trong Golang chúng ta có thể viết các service http hiệu suất cao với sự trợ giúp của thư viện chuẩn. Đây là một service hello world đơn giản:
package main
import (
"io"
"log"
"net/http"
)
func sayhello(wr http.ResponseWriter, r *http.Request) {
wr.WriteHeader(200)
io.WriteString(wr, "hello world")
}
func main() {
http.HandleFunc("/", sayhello)
err := http.ListenAndServe(":9090", nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
Chúng ta sẽ đo throughput của Web service này: sử dụng wrk trên máy tính cá nhân có cấu hình:
ThinkPad-T470
-------------------------------
OS: Ubuntu 18.04.2 LTS x86_64
Host: 20HES39900 ThinkPad T470
Kernel: 4.15.0-52-generic
CPU: Intel i5-7200U (4) @ 3.100GHz
GPU: Intel HD Graphics 620
Memory: 2977MiB / 15708MiB
Kết quả test:
$ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 360.57us 769.72us 14.27ms 91.45%
Req/Sec 7.07k 0.91k 9.25k 76.10%
704529 requests in 10.01s, 86.00MB read
Requests/sec: 70363.89
Transfer/sec: 8.59MB
$ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 395.85us 0.90ms 18.93ms 91.88%
Req/Sec 6.92k 0.95k 9.34k 75.30%
688941 requests in 10.02s, 84.10MB read
Requests/sec: 68783.96
Transfer/sec: 8.40MB
$ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 374.92us 814.34us 13.76ms 91.47%
Req/Sec 7.09k 1.03k 21.18k 82.82%
706968 requests in 10.09s, 86.30MB read
Requests/sec: 70040.20
Transfer/sec: 8.55MB
Kết quả của thử nghiệm là khoảng 70.000 QPS và thời gian phản hồi là khoảng 15ms. Đối với một ứng dụng web, đây đã là một kết quả rất tốt. Đây chỉ là một máy tính cá nhân nên với server có cấu hình cao hơn sẽ đạt được kết quả còn tốt hơn nữa.
Chương trình của chúng ta chưa có chứa logic nghiệp vụ nên có thể dễ dàng đánh giá được QPS như thế, trên thực tế khi gặp một mô-đun có số lượng logic nghiệp vụ lớn và số lượng code lớn, thì vấn đề bottleneck có thể phải trả qua nhiều lần stress test mới có thể phát hiện ra.
Một số hệ thống thường bị bottleneck do mạng, chẳng hạn như dịch vụ CDN và dịch vụ Proxy. Một số là do CPU/GPU, như các dịch vụ xác minh đăng nhập và dịch vụ xử lý hình ảnh. Số khác do truy cập vào disk bị tắc nghẽn như hệ thống lưu trữ, cơ sở dữ liệu. Các nút thắt chương trình khác nhau được phản ánh ở những nơi khác nhau và các dịch vụ đơn chức năng được đề cập ở trên tương đối dễ phân tích.
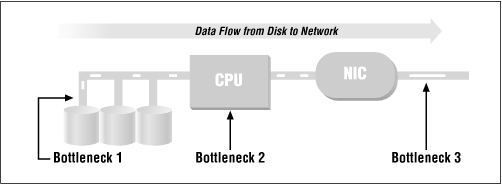
3 nơi có khả năng tắc nghẽn: disk, CPU, NIC
Đối với trường hợp nút cổ chai IO/Network, throughput ở chỗ NIC/disk IO (NIC - Network Interface Card) sẽ đầy trước CPU. Trong trường hợp này, ngay cả khi CPU được tối ưu hóa, throughput của toàn bộ hệ thống vẫn không thể cải thiện mà chỉ có thể tăng tốc độ đọc ghi của đĩa lên. Kích thước memory lớn có thể làm tăng băng thông của NIC để cải thiện hiệu suất tổng thể. Chương trình bottleneck ở CPU là khi mức sử dụng CPU đạt 100% trước lúc bộ nhớ và NIC đầy. CPU luôn ở tình trạng "busy" với nhiều tác vụ tính toán khác nhau trong khi các thiết bị IO thường tương đối nhàn rỗi (phần lớn thời gian ở trạng thái chờ).
Bất kể là loại service nào, một khi tài nguyên sử dụng đạt đến giới hạn các request sẽ bị dồn lại, khi hết timeout mà không kịp xử lí sẽ dẫn đến treo hệ thống (không phản hồi) và ảnh hưởng trực tiếp tới người dùng cuối. Đối với các Web service phân tán, bottleneck không phải lúc nào cũng nằm trong hệ thống mà nó có thể nằm ở bên ngoài. Các hệ thống không chuyên về tính toán có xu hướng sẽ gặp vấn đề ở cơ sở dữ liệu quan hệ và lúc đó chính bản thân mô-đun Web đã bị bottleneck.
Không quan trọng service của chúng ta bị bottleneck tại đâu, vấn đề cuối cùng vẫn giống nhau đều nằm ở công việc quản lý lưu lượng (traffic).
4.6.1 Tầm quan trọng của giới hạn lưu lượng
Có nhiều cách để giới hạn lưu lượng. Phổ biến nhất là leaky buckets và token buckets.
- Leaky bucket có thể hiểu rằng chúng ta có một cái xô chứa đầy nước, và một giọt nước rò rỉ ra sau mỗi khoảng thời gian cố định. Nếu nhận được "giọt nước" thì có thể tiếp tục yêu cầu dịch vụ, ngược lại thì cần phải đợi đến lần nhỏ giọt tiếp theo.
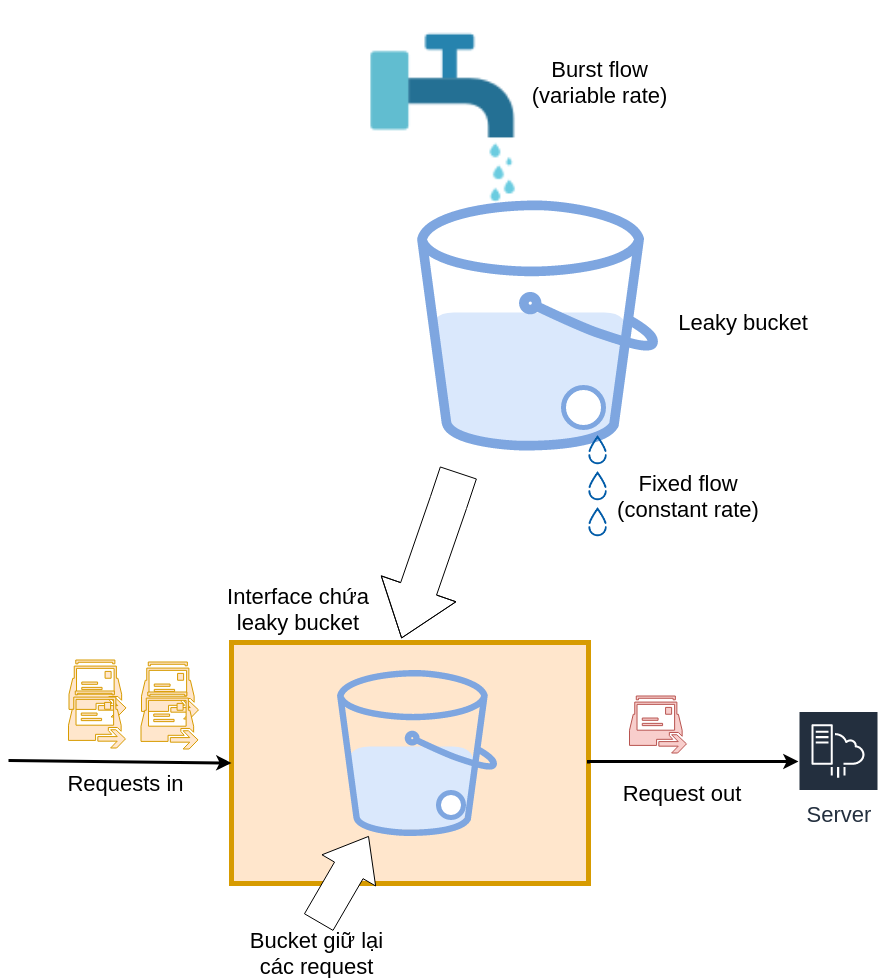
Minh hoạ Leaky bucket
- Token bucket với nguyên tắc token được thêm vào bucket với tốc độ (rate) không đổi. Để có được token từ bucket, số lượng token có thể được điều chỉnh theo số tài nguyên cần sử dụng. Nếu không có token, ta có thể lựa chọn tiếp tục chờ hoặc từ bỏ. Hai phương pháp này nhìn thì tương tự nhau, nhưng thực ra là có một vài điểm khác biệt.
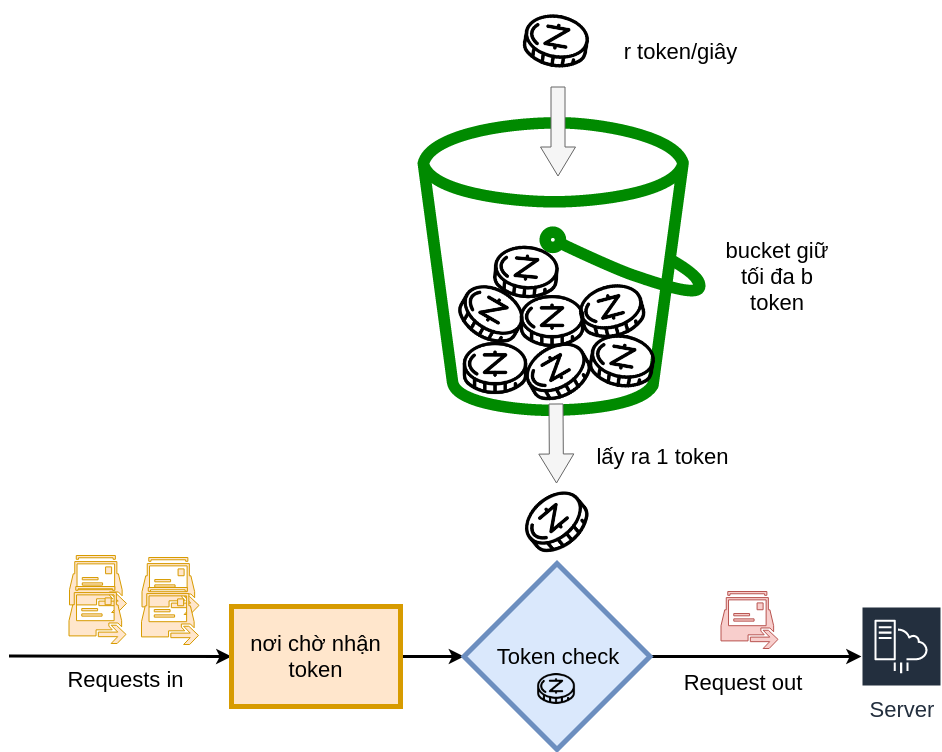
Minh hoạ Token bucket
- Tốc độ mà leaky bucket bị rò rỉ (leak) là cố định còn token trong token bucket có thể được lấy ra chỉ khi có token trong bucket.
- Điều đó nghĩa là token bucket chỉ cho phép một mức độ đồng thời nhất định. Ví dụ cùng lúc có 100 yêu cầu người dùng gửi tới, miễn là có 100 token trong bucket thì tất cả 100 yêu cầu sẽ được đưa ra.
- Token bucket cũng có thể suy biến thành mô hình leaky bucket nếu không có token trong bucket.
Trong các ứng dụng thực tế, token bucket được sử dụng rộng rãi và hầu hết các limiter phổ biến hiện nay trong cộng đồng Open source đều dựa trên token bucket. Trên cơ sở này, có một phiên bản limiter là juju/ratelimit cung cấp một số phương thức thêm vào token với các đặc điểm khác nhau như sau:
// fillInterval với ý nghĩa mỗi token sẽ được đặt trong bucket
// một khoảng thời gian time.Duration, số lượng tối đa là
// capacity của bucket, phần vượt quá capacity sẽ bị loại bỏ.
// các bucket được khởi tạo ban đầu đều ở trạng thái đầy.
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket
// khác biệt so với NewBucket() thông thường là cho phép đưa vào
// một kích thước quantum nhất định - quantum tokens ở mỗi
// khoảng thời gian fillInterval.
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket
// NewBucketWithRate trả về một bucket token với số token được
// đưa vào mỗi giây đạt đến công suất tối đa rate.
// Do độ phân giải hạn chế của clock nên ở tốc độ cao thì tỷ lệ
// thực tế có thể khác tới 1% so với tỷ lệ được chỉ định.
// Ví dụ capacity=100, và rate=0.1, sẽ được một bucket có thể
// thêm vào 10 tokens mỗi giây.
func NewBucketWithRate(rate float64, capacity int64) *Bucket
Việc nhận token từ bucket cũng được cung cấp một số API:
func (tb *Bucket) Take(count int64) time.Duration {}
func (tb *Bucket) TakeAvailable(count int64) int64 {}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration)
(time.Duration, bool,) {}
func (tb *Bucket) Wait(count int64) {}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool {}
Tên và chức năng tương của chúng khá đơn giản nên ta sẽ không đi vào chi tiết ở đây. So với công cụ ratelimiter do thư viện Java của Google cung cấp là Guava nổi tiếng hơn trong cộng đồng Open source, thư viện này không hỗ trợ khởi tạo token và không thể sửa đổi dung lượng token ban đầu, do đó có thể không đáp ứng được hết các yêu cầu trong các trường hợp riêng lẻ.
4.6.2 Nguyên tắc
Mô hình token bucket thực ra là một quá trình cộng trừ vào một biến đếm toàn cục, nhưng việc sử dụng biến chung đòi hỏi chúng ta phải thêm các khóa đọc-ghi, chính vì vậy mà trở nên phức tạp. Nếu chúng ta đã quen thuộc với ngôn ngữ Go, bạn có thể nghĩ ngay đến việc dùng một buffered channel để hoàn thành thao tác tạo ra token bucket đơn giản:
var tokenBucket = make(chan struct{}, capacity)
tokenBucket thêm token vào theo thời gian, nếu bucket đã đầy thì bỏ qua:
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
Kết hợp vào code:
package main
import (
"fmt"
"time"
)
func main() {
var fillInterval = time.Millisecond * 10
var capacity = 100
var tokenBucket = make(chan struct{}, capacity)
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
go fillToken()
time.Sleep(time.Hour)
}
Kết quả sau khi thực thi thu được:
current token cnt: 98 2019-06-21 13:49:01.932273966 +0700 +07 m=+0.980163041
current token cnt: 99 2019-06-21 13:49:01.942302937 +0700 +07 m=+0.990192005
current token cnt: 100 2019-06-21 13:49:01.952350569 +0700 +07 m=+1.000239633
current token cnt: 100 2019-06-21 13:49:01.962330944 +0700 +07 m=+1.010220033
current token cnt: 100 2019-06-21 13:49:01.972302925 +0700 +07 m=+1.020191986
current token cnt: 100 2019-06-21 13:49:01.982292881 +0700 +07 m=+1.030181989
current token cnt: 100 2019-06-21 13:49:01.992308344 +0700 +07 m=+1.040197432
current token cnt: 100 2019-06-21 13:49:02.002350638 +0700 +07 m=+1.050239734
current token cnt: 100 2019-06-21 13:49:02.012318649 +0700 +07 m=+1.060207734
current token cnt: 100 2019-06-21 13:49:02.022282122 +0700 +07 m=+1.070171206
Trong thời gian 1s chương trình đưa ra 100 token. Tuy nhiên có thể thấy bộ đếm thời gian của Go có lỗi khoảng 0,001 giây, vì vậy nếu kích thước bucket lớn hơn 1000, có thể xảy ra một số lỗi. Mặc dù đối với phần lớn service thì lỗi này không đáng kể.
Thao tác cấp token của token bucket ở trên cũng dễ hiện thực hơn, để đơn giản hóa vấn đề, ta chỉ lấy một token như sau đây:
func TakeAvailable(block bool) bool{
var takenResult bool
if block {
select {
case <-tokenBucket:
takenResult = true
}
} else {
select {
case <-tokenBucket:
takenResult = true
default:
takenResult = false
}
}
return takenResult
}
Ở đây chú ý một chút, token bucket đưa token vào bucket theo các khoảng thời gian cố định. Giả sử:
- Lần cuối token được đưa vào là t1,
- Số token tại thời điểm đó là k1,
- Time interval là ti,
- Mỗi lần đưa x token vào bucket,
- Dung lượng của bucket là giới hạn.
Bây giờ nếu ai đó gọi TakeAvailable để lấy n token, ta sẽ ghi lại khoảnh khắc này là t2. Vây tại t2 nên có bao nhiêu token trong bucket token? Mã giả như sau:
cur = k1 + ((t2 - t1)/ti) * x
cur = cur > cap ? cap : cur
Chúng ta sử dụng chênh lệch thời gian giữa t1, t2 kết hợp với các tham số ti, k1 thì có thể biết được số lượng token trong bucket trước khi lấy ra token. Về mặt lý thuyết là không cần thiết sử dụng hoạt động điền token vào channel ở ví dụ trước. Miễn là mỗi lần ta đều tính số lượng token trong bucket thì có thể nhận được số lượng token chính xác. Sau khi nhận được số lượng token rồi thì chỉ cần thực hiện những thao tác cần thiết như phép trừ số lượng token. Hãy nhớ sử dụng lock để đảm bảo an toàn với tính concurrency. Thư viện juju/ratelimit đang thực hiện theo cách này.
4.6.3 Vấn đề tắc nghẽn Service và Quality of Service
Trước đây chúng ta đã nói nhiều về việc bottleneck ở CPU, IO và một số loại khác nữa, vấn đề này có thể phát hiện tương đối nhanh chóng từ hầu hết các công ty có monitoring, nếu hệ thống gặp vấn đề về hiệu suất thì quan sát biểu đồ monitor về response là phương án nhanh nhất để phát hiện nguyên nhân.
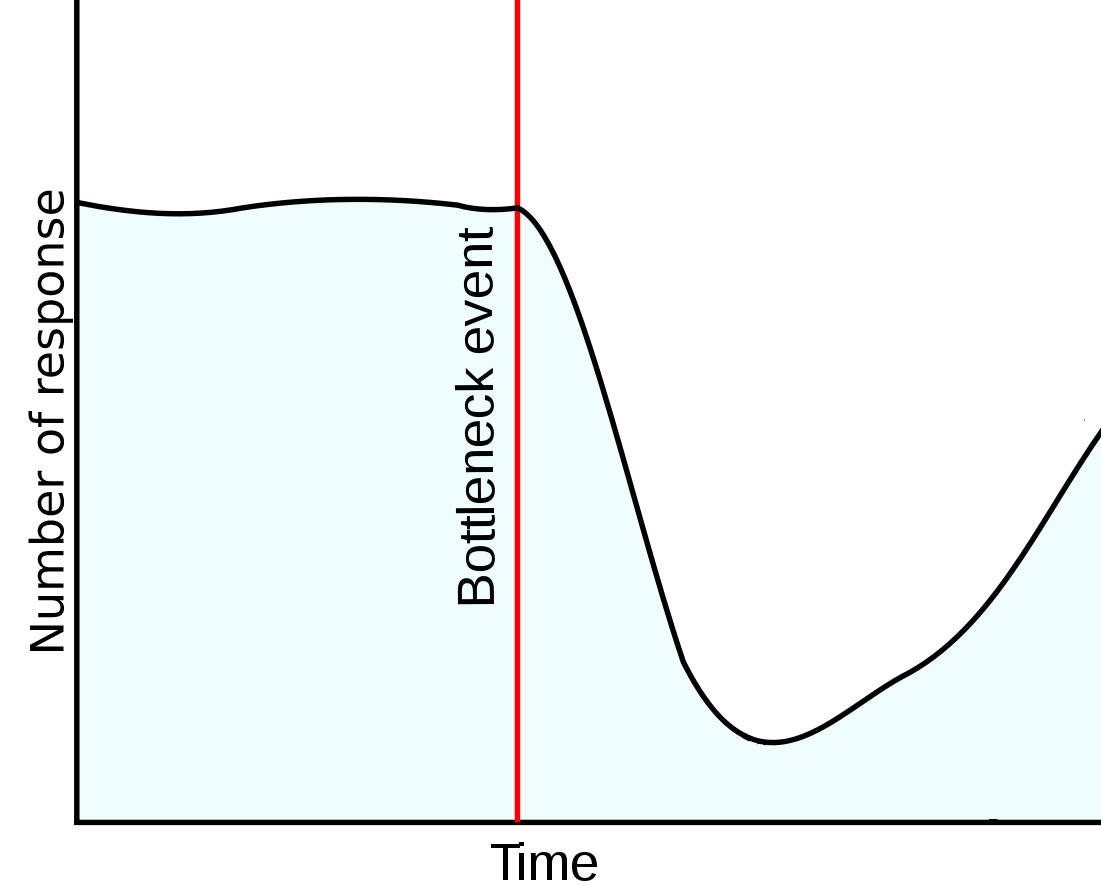
Biểu đồ để phát hiện bottleneck
Mặc dù các số liệu hiệu suất là quan trọng, QoS (Quality of Service) tổng thể của dịch vụ cũng cần được xem xét khi cung cấp dịch vụ cho người dùng. QoS bao gồm các số liệu như tính sẵn sàng (availability), thông lượng (throughput), độ trễ (latency, delay variation), mất mát dữ liệu, ...
Nhìn chung, ta có thể cải thiện việc sử dụng CPU của các dịch vụ Web bằng cách tối ưu hóa hệ thống, từ đó tăng throughput của toàn bộ hệ thống.
Nhưng khi throughput được cải thiện, chưa chắc đã có thể cải thiện trải nghiệm người dùng. Người dùng rất nhạy cảm với độ trễ. Dù throughput của hệ thống cao, nhưng nếu không phản hồi được trong một thời gian dài sẽ làm người dùng rất khó chịu. Do đó, trong các chỉ số hiệu suất dịch vụ Web của các công ty lớn, ngoài độ trễ phản hồi trung bình, thời gian phản hồi 95% (p95) và 99% (p99) cũng được lấy ra làm tiêu chuẩn hiệu suất. Thời gian phản hồi trung bình thường không ảnh hưởng nhiều đến việc cải thiện hiệu suất sử dụng CPU, quan trọng là thời gian phản hồi 99% so với 95% có thể tăng đáng kể. Từ đó ta có thể xem xét liệu chi phí cải thiện hiệu suất sử dụng CPU này có đáng hay không.
Liên kết
- Phần tiếp theo: Mô hình của các dự án web
- Phần trước: Làm việc với Database
- Mục lục